Django ORM 源码浅析
Django 是一个由 Python 写成的开源的重量级的 Web 应用框架,采用 MVT 的软件设计模式,即模型(Model),视图(View)和模板(Template)。
Django 集成了一个功能强大的 ORM 框架,基本上支持主流数据库的 SQL 语法执行。
ORM(Object Relational Mapping,即对象关系映射),是一种程序设计技术,用于实现面向对象编程语言和数据库 SQL 的映射。
ORM 框架设计时通常需要考虑以下几个问题:
- 对象和数据库相关概念的映射
- 对象如何转换成 SQL
- SQL 执行结果如何转换成对象
- 多数据库的支持
下面通过对 Django-2.0.2 源码的分析来了解 Django ORM 是如何解决上述几个问题的。
前置知识
在分析 ORM 源码之前需要了解一些前置知识:Django ORM API 的简单使用,Python 迭代器,Python 元类编程。前面两点相对简单,所以提供了快速入门的教程供参考。这里重点说一下 Python 元类编程。
因为 ORM 比如 Model 是用户自定义的,所以没法事先就在代码里定义好所有信息,需要在运行时根据用户定义的 Model 信息去动态地创建 Model 类。
Python 是动态语言,用来写 ORM 是非常便利了。
在 Python 中,定义一个类可以这么写:
class Hello(object):
def hello(x):
return x
也可以这么写:
# 三个参数分别是 class 名称,继承的父类集合,属性方法
type("Hello", (object,), dict(hello=lambda x: x))
Python 解析器在遇到 class 定义时是调用 type 函数动态创建类的,所以两种写法本质是一样的。
class 定义类时可以传递 metaclass 设置,Python 解析器会将当前要创建的类传递到元类的 __new__ 方法中。
class Hello(metaclass=HelloMetaclass):
pass
class HelloMetaclass(type):
# 四个参数分别是要创建的类,类名,类继承的父类集合,类属性方法集合
def __new__(cls, name, bases, attrs):
# 可以自定义类的动态初始化过程
......
源码文件结构
Django ORM 的源码实现基本上都在 db 模块下,db 模块主要包括 backends 和 models 两个子模块。
backends 模块提供多数据库的支持,用于不同数据库的 SQL 差异化处理;
models 模块提供 Python 对象到数据库概念的映射和互相转换,这部分是核心代码。
├── backends
│ ├── base
│ ├── dummy 哑后端,什么都不做,定义空方法
│ ├── mysql Mysql 后端实现
│ ├── oracle Oracle 后端实现
│ ├── postgresql
│ ├── postgresql_psycopg2
│ ├── sqlite3
├── migrations 猜测是通过 Model 迁移生成数据表的相关代码
├── models
│ ├── fields
│ │ ├── __init__.py 数据库字段的封装类 Field 及其子类(重点)
│ │ ├── files.py 文件相关字段类
│ ├── functions
│ ├── sql
│ │ ├── compiler.py SQL 编译器类,用于拼接生成 SQL 语句(重点)
│ │ ├── query.py Select SQL 语句的封装类 Query(重点)
│ │ ├── subqueries.py 增删改 SQL 语句的封装类,比如:DeleteQuery,UpdateQuery,InsertQuery
│ ├── aggregates.py 聚合函数,比如 Sum,Count,Min,Avg
│ ├── base.py Model 类和 ModelBase 元类(重点)
│ ├── deletion.py 外键删除的级联操作,比如 CASCADE,SET_NULL,DO_NOTHING
│ ├── expressions.py SQL 表达式相关类,比如 CASE,WHEN,ORDER_BY
│ ├── indexes.py 索引类
│ ├── manager.py Model 管理类,比如:Manager 类和 BaseManager 类(重点)
│ ├── options.py Model 类的 meta 元信息封装
│ ├── query.py QuerySet 的主要实现,提供 ORM 的 公共 API 接口(重点)
│ ├── signals.py Model 的信号量
├── transaction.py 事务管理相关
├── utils.py 工具类代码,主要包括数据库连接和路由管理
最重要的几个类及其交互
models 模块下有以下这些重要的类用于封装数据库概念和相关操作:
- ModelBase:所有 Model 类(包括用户自定义的)的元类,定义了动态创建 Model 类的整个初始化过程
- Model:所有用户自定义的 Model 都需要继承这个类,映射为数据库中的表
- Option:Model 类中可以定义 Meta 内部类,这些 Model 元信息会被封装进 Option 中
- Field:所有不同数据类型字段的父类,映射为数据库的表字段
- Manager:每一个 Model 类至少要有一个 Manager 对象,用于管理数据库操作,可以看成数据库执行操作的入口
- QuerySet:查询结果集,封装了 SQL 执行的结果数据,注意 QuerySet 是惰性计算的
- Query:封装了具体一条 SQL 的全部信息,映射为数据库中一条具体的执行 SQL
- SQLCompiler:SQL 语句编译器,编译 Query 对象拼接生成最终执行的 SQL
简单画个了类图表示这些类是如何连接起来并进行交互的。注意:
- 只画了重点的类和属性方法,避免臃肿
- ModelBase 是 Model 的元类,图里简单理解为 Model 继承自 ModelBase
- BaseManagerFromQuerySet 是 BaseManager 的 from_queryset 方法动态创建的类,代码里并没有 class 定义
- Query 的 compiler 属性指向的是字符串 “SQLComplier”,图里简单理解为聚合了 SQLComplier 对象
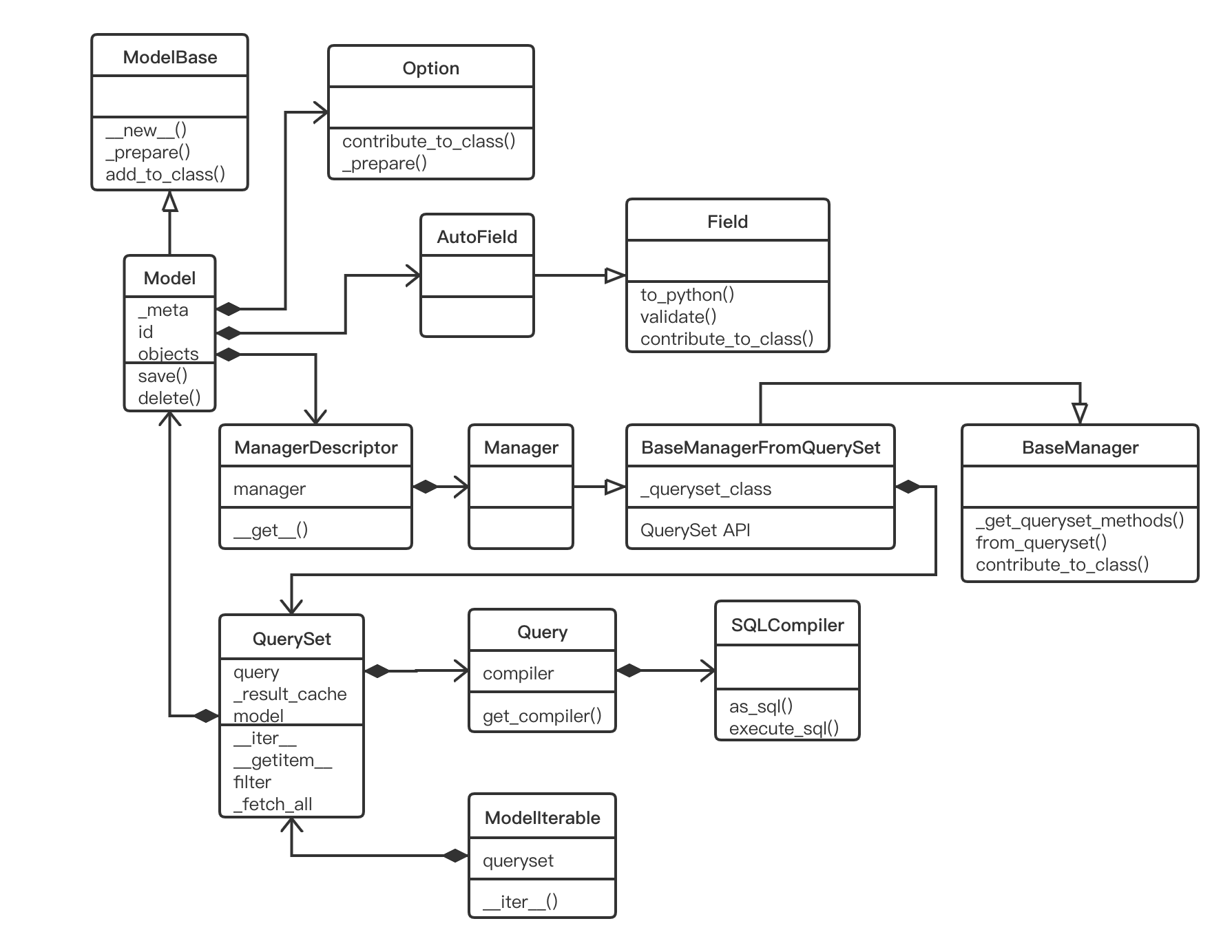
接下来通过代码分析每个类具体是干什么的。因为很多类的代码量都比较多,所以只列出了重点的属性和方法,对于比较长的方法,只列出了重点代码行并做注释,其余代码行用 …… 表示忽略。代码注释中的 Model 类一般指的用户自定义的 Model 类。每个类会给出具体模块路径和代码行,方便快速定位代码。
ModelBase
# django/db/models/base.py 71
class ModelBase(type):
"""Metaclass for all models."""
def __new__(cls, name, bases, attrs):
super_new = super().__new__
# 确保只对 Model 的子类执行以下的动态初始化过程,对于 Model 自身直接创建即可
parents = [b for b in bases if isinstance(b, ModelBase)]
if not parents:
return super_new(cls, name, bases, attrs)
# Create the class.
module = attrs.pop('__module__')
new_attrs = {'__module__': module}
classcell = attrs.pop('__classcell__', None)
if classcell is not None:
new_attrs['__classcell__'] = classcell
new_class = super_new(cls, name, bases, new_attrs) # 动态创建新的 Model 类
attr_meta = attrs.pop('Meta', None)
abstract = getattr(attr_meta, 'abstract', False)
# 如果当前要创建的 Model 子类有定义 Meta 内部类,使用该 Meta 类;否则使用父类 Model 定义的 Meta 内部类
if not attr_meta:
meta = getattr(new_class, 'Meta', None)
else:
meta = attr_meta
......
new_class.add_to_class('_meta', Options(meta, app_label)) # 往当前创建的 Model 类设置 _meta 属性,指向 Option 对象
......
# 往当前 Model 类设置各种属性方法
for obj_name, obj in attrs.items():
new_class.add_to_class(obj_name, obj)
......
new_class._prepare() # 确保每个 Model 类至少有一个 Manager 对象
new_class._meta.apps.register_model(new_class._meta.app_label, new_class)
return new_class # 返回创建成功的 Model 类
def add_to_class(cls, name, value):
# 如果要设置的属性指向的对象有绑定 contribute_to_class 方法
if not inspect.isclass(value) and hasattr(value, 'contribute_to_class'):
value.contribute_to_class(cls, name)
else:
setattr(cls, name, value)
def _prepare(cls):
"""Create some methods once self._meta has been populated."""
......
if not opts.managers:
if any(f.name == 'objects' for f in opts.fields):
raise ValueError(
"Model %s must specify a custom Manager, because it has a "
"field named 'objects'." % cls.__name__
)
manager = Manager()
manager.auto_created = True
# 最终调用 Manager 对象的 contribute_to_class 方法
cls.add_to_class('objects', manager)
......
ModelBase 是所有 Model 类(包括用户自定义的)的元类。
Django 在启动时会依次遍历每个 app,加载 app 的 model.py 模块下的 Model 类,然后调用 ModelBase 的 __new__ 方法对每个 Model 类进行动态创建和初始化。
__new__ 方法做的工作主要有:设置 _meta 属性,设置各种属性方法到 Model 类中,调用 _prepare 方法确保每个 Model 类至少绑定有一个 Manager(默认命名为 objects)。
Model
# django/db/models/base.py 393
class Model(metaclass=ModelBase):
def _do_insert(self, manager, using, fields, update_pk, raw):
# Manager 会从 QuerySet 复制 _insert 方法过来,所以这里最终是调用 QuerySet 的 _insert 方法
return manager._insert([self], fields=fields, return_id=update_pk,
using=using, raw=raw)
Django 规定,所有用户自定义的 Model 都必须继承自这个 Model 父类,可以理解成对应数据库中的表。
Python 在动态解析创建类的过程中,会从当前类一直上溯找其父类,看是否有设置 metaclass,所以所有用户自定义的 Model 最终都会通过 ModelBase 进行动态初始化。
Model 类中主要定义有 save,delete 和各种索引、约束、字段的校验方法,比如第 944 行的validate_unique 和 第 1194 行的 check 方法。
Model 的 save 方法有创建和更新的功能,save 方法的函数调用链是这样的:save -> save_base -> _save_table -> _do_insert/_do_update,所以最终会调用 QuerySet 的 _insert 和 _update 方法,这个后续 QuerySet 部分继续讲。
Option
# django/db/models/options.py 69
class Options:
# Model 类的 _meta 属性封装的全部元信息
FORWARD_PROPERTIES = {
'fields', 'many_to_many', 'concrete_fields', 'local_concrete_fields',
'_forward_fields_map', 'managers', 'managers_map', 'base_manager',
'default_manager',
}
REVERSE_PROPERTIES = {'related_objects', 'fields_map', '_relation_tree'}
# 在 ModelBase __new__ 方法中通过 add_to_class 方法被调用, cls 指向 Model 类, name = '_meta'
# 对 Meta 内部类的属性值进行检查并设置到 _meta 属性上
def contribute_to_class(self, cls, name):
......
# Model 类的 _meta 属性指向当前 Option 对象
cls._meta = self
......
def _prepare(self, model):
......
# 如果 Model 类没有设置主键,则往 Model 类添加自增 ID 主键
if self.pk is None:
......
auto = AutoField(verbose_name='ID', primary_key=True, auto_created=True)
model.add_to_class('id', auto)
Model 类中可以定义 Meta 内部类,这些元信息会被封装进 Option 对象中,用 _meta 属性指向。
Field
# django/db/models/fields/__init__.py 89
@total_ordering
class Field(RegisterLookupMixin):
"""Base class for all field types"""
# 对字段进行合法性检查
def check(self, **kwargs):
errors = []
errors.extend(self._check_field_name())
errors.extend(self._check_choices())
errors.extend(self._check_db_index())
errors.extend(self._check_null_allowed_for_primary_keys())
errors.extend(self._check_backend_specific_checks(**kwargs))
errors.extend(self._check_validators())
errors.extend(self._check_deprecation_details())
return errors
# 数据库类型到 Python 类型的转换,由子类覆写
def to_python(self, value):
return value
# 对字段值进行校验,子类可以覆写该方法实现自定义校验逻辑
def validate(self, value, model_instance):
......
# 在 ModelBase 的 __new__ 方法中被调用,cls 指向要创建的 Model 类
def contribute_to_class(self, cls, name, private_only=False):
self.set_attributes_from_name(name)
self.model = cls
# 往 Model 类的 _meta 属性添加当前字段
if private_only:
cls._meta.add_field(self, private=True)
else:
cls._meta.add_field(self)
# 往 Model 类添加当前字段
if self.column:
if not getattr(cls, self.attname, None):
setattr(cls, self.attname, DeferredAttribute(self.attname, cls))
if self.choices:
setattr(cls, 'get_%s_display' % self.name,
partialmethod(cls._get_FIELD_display, field=self))
models/fields/__init__.py 模块中定义了多种不同数据类型的 Field 子类,该模块的 __all__ 列出了 Model 类中支持的所有数据类型。
Manager
# django/db/models/manager.py 167
class Manager(BaseManager.from_queryset(QuerySet)):
pass
每一个 Model 类至少要有一个 Manager 对象,用于管理数据库操作。
在 Model 类的动态创建过程中,如果当前 Model 没有封装任何 Manager 对象,则会自动创建 Manager 对象,用 objects 属性指向。
看 Manager 的类定义,没有定义任何东西,直接继承自 BaseManager 的 from_queryset 方法动态创建返回的类。
再看 BaseManager 类的代码。
# django/db/models/manager.py 9
class BaseManager:
@classmethod
def _get_queryset_methods(cls, queryset_class):
# 从 QuerySet 获取方法对象,复制相关属性,动态生成 Manager 的方法
def create_method(name, method):
def manager_method(self, *args, **kwargs):
return getattr(self.get_queryset(), name)(*args, **kwargs)
manager_method.__name__ = method.__name__
manager_method.__doc__ = method.__doc__
return manager_method
new_methods = {}
# 获取 QuerySet 中的公开成员方法,排除以 '_' 开头的私有方法
for name, method in inspect.getmembers(queryset_class, predicate=inspect.isfunction):
# Only copy missing methods.
if hasattr(cls, name):
continue
# Only copy public methods or methods with the attribute `queryset_only=False`.
queryset_only = getattr(method, 'queryset_only', None)
if queryset_only or (queryset_only is None and name.startswith('_')):
continue
# Copy the method onto the manager.
new_methods[name] = create_method(name, method)
return new_methods
@classmethod
def from_queryset(cls, queryset_class, class_name=None):
if class_name is None:
class_name = '%sFrom%s' % (cls.__name__, queryset_class.__name__)
class_dict = {
'_queryset_class': queryset_class,
}
class_dict.update(cls._get_queryset_methods(queryset_class))
# 动态创建 BaseManagerFromQuerySet 类,继承自 BaseManager
# 类的属性包括有 _queryset_class,指向 QuerySet 类
# 类的方法包括有 QuerySet 类中的公共方法
return type(class_name, (cls,), class_dict)
# 在 ModelBase __new__ 方法中通过 _prepare 方法被调用, name = 'objects'
def contribute_to_class(self, model, name):
if not self.name:
self.name = name
self.model = model
# 往 Model 类中设置 objects 属性,指向包装过后的 Manager 对象
setattr(model, name, ManagerDescriptor(self))
# 往 Model 类的 _meta 属性(即 Option 对象)添加当前 Manager 对象
model._meta.add_manager(self)
# self.db 时调用,返回数据库别名
@property
def db(self):
return self._db or router.db_for_read(self.model, **self._hints)
def get_queryset(self):
return self._queryset_class(model=self.model, using=self._db, hints=self._hints)
def all(self):
# Model.objects.all() 其实返回的是 QuerySet 对象
return self.get_queryset()
BaseManager 的 from_queryset 方法动态创建并返回继承自 BaseManager 自身的 BaseManagerFromQuerySet 类,Manager 继承自 BaseManagerFromQuerySet,所以 Manager 类中也包含有 all,contribute_to_class 和 QuerySet 中的 公开 API 方法。所以 Manager 其实本身也可以看成是 QuerySet。
Manager 对象调用 contribute_to_class 方法会往当前 Manager 对象所属 Model 类中添加 objects 属性,指向包装了当前 Manager 对象的 ManagerDescriptor 对象,而不是指向当前 Manager 对象。
再继续看 ManagerDescriptor 的代码。
# django/db/models/manager.py 171
class ManagerDescriptor:
def __init__(self, manager):
self.manager = manager
# User.objects 和 user.objects 会调用这个魔法方法
def __get__(self, instance, cls=None):
# Manager 不允许通过类实例调用
if instance is not None:
raise AttributeError("Manager isn't accessible via %s instances" % cls.__name__)
......
return cls._meta.managers_map[self.manager.name] # 返回 Manager 对象
Django 规定,只有 Model 类可以调用 objects,Model 对象不可以。
这点也比较好理解,Model 类对应数据表,Model 对象对应具体一条记录,可以对数据表进行查询过滤,而没法对记录进行查询过滤。
ManagerDescriptor 仅仅是对 Manager 进行了一层封装,限制了 Manager 的访问权限,真正工作的还是 Manager 自身。
QuerySet
# django/db/models/query.py 44
class ModelIterable(BaseIterable):
"""Iterable that yields a model instance for each row."""
def __iter__(self):
queryset = self.queryset
db = queryset.db 将 QuerySet 的 db 属性(即数据库别名)通过 Query 传递到编译器中
compiler = queryset.query.get_compiler(using=db) # 通过 Query 对象获取编译器
# 真正执行 SQL 的地方!!!
results = compiler.execute_sql(chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size)
......
for row in compiler.results_iter(results):
obj = model_cls.from_db(db, init_list, row[model_fields_start:model_fields_end])
......
yield obj # 惰性返回结果
# django/db/models/query.py 182
class QuerySet:
"""Represent a lazy database lookup for a set of objects."""
def __init__(self, model=None, query=None, using=None, hints=None):
self.model = model
self._db = using
self._hints = hints or {}
self.query = query or sql.Query(self.model) # 封装 Query 对象
self._result_cache = None # 用于缓存结果,减少数据库访问次数,每次增删改都需要清空缓存
......
self._iterable_class = ModelIterable # 用于惰性计算返回 Model 对象
......
# for 循环 QuerySet 时会调用这个魔法方法
def __iter__(self):
# 查询数据库,将结果放入 _result_cache 缓存
self._fetch_all()
# 将 _result_cache 缓存变成惰性获取的序列
return iter(self._result_cache)
# 对 QuerySet 切片([m: n]) 或取具体下标([n]) 会调用这个魔法方法
def __getitem__(self, k):
"""Retrieve an item or slice from the set of results."""
if not isinstance(k, (int, slice)):
raise TypeError
assert ((not isinstance(k, slice) and (k >= 0)) or
(isinstance(k, slice) and (k.start is None or k.start >= 0) and
(k.stop is None or k.stop >= 0))), \
"Negative indexing is not supported."
# 如果缓存有数据,直接从缓存中取,不用再查数据库
if self._result_cache is not None:
return self._result_cache[k]
# k 为切片时获取多条记录
if isinstance(k, slice):
qs = self._chain()
if k.start is not None:
start = int(k.start)
else:
start = None
if k.stop is not None:
stop = int(k.stop)
else:
stop = None
qs.query.set_limits(start, stop) # 可以理解为设置查询 SQL 的 limit, offset
return list(qs)[::k.step] if k.step else qs
# k 为具体下标时获取具体一条记录
qs = self._chain()
qs.query.set_limits(k, k + 1)
qs._fetch_all()
return qs._result_cache[0]
# 创建 Model 对象并调用 save 方法
# 在上面 Model 类中已经分析过了,最终 Model.save 还是会调用 QuerySet._insert 方法
def create(self, **kwargs):
obj = self.model(**kwargs)
self._for_write = True
obj.save(force_insert=True, using=self.db)
return obj
def filter(self, *args, **kwargs):
return self._filter_or_exclude(False, *args, **kwargs)
def _filter_or_exclude(self, negate, *args, **kwargs):
if args or kwargs:
assert self.query.can_filter(), \
"Cannot filter a query once a slice has been taken."
clone = self._chain() # 复制生成一个新的 QuerySet 对象
if negate:
clone.query.add_q(~Q(*args, **kwargs)) # exclude 方法走这里
else:
clone.query.add_q(Q(*args, **kwargs)) # filter 方法走这里
return clone
def _insert(self, objs, fields, return_id=False, raw=False, using=None):
self._for_write = True
if using is None:
using = self.db
query = sql.InsertQuery(self.model) # 创建 InsertQuery 对象
query.insert_values(fields, objs, raw=raw)
# 通过 InsertQuery 的 SQLInsertCompiler 编译器执行 Insert SQL
# 具体代码查看 django/db/models/sql/complier.py 的 SQLInsertCompiler 类的 execute_sql 和 as_sql 方法
# 在 as_sql 方法中可以看到 INSERT INTO 字样
return query.get_compiler(using=using).execute_sql(return_id)
def _fetch_all(self):
if self._result_cache is None:
# 在 __init__ 中,_iterable_class 指向 ModelIterable 类
# 对 ModelIterable 对象调用 list() 即调用 ModelIterable 类的 __iter___ 魔法方法
self._result_cache = list(self._iterable_class(self))
if self._prefetch_related_lookups and not self._prefetch_done:
self._prefetch_related_objects()
QuerySet 查询结果集,我们常用的各种增删改查 API 都定义在这个类中,比如:create,filter,get_or_create 等等。
ModelIterable 封装 QuerySet,使得 QuerySet 是惰性计算返回的。
# 返回的 users 只是 QuerySet 对象,此时还没有执行 SQL
users = User.objects.filter(age=18)
# 只有进行了如下操作才真正执行 SQL
list(users) # 调用 QuerySet 的 __iter__ 方法
users[0] # 调用 QuerySet 的 __getitem__ 方法
Query
# django/db/models/sql/query.py 130
class Query:
"""A single SQL query."""
compiler = 'SQLCompiler' # 封装了用于编译该 Select SQL 的编译器
# 创建 SQLCompiler 编译器对象
def get_compiler(self, using=None, connection=None):
if using is None and connection is None:
raise ValueError("Need either using or connection")
if using:
connection = connections[using]
return connection.ops.compiler(self.compiler)(self, connection, using)
通过 Query 类的 __init__构造方法可以分析,Query 其实是 Select 语句的对象封装,封装了 Select 语句的诸如 select,where,join,group_by 等等信息。
在 models/sql/subqueries.py 模块下还定义有 DeleteQuery、UpdateQuery、InsertQuery 和 AggregateQuery,都继承自 Query 类,分别是 Delete、Update、Insert 和包含聚合功能的 Select 语句的对象封装。
SQLCompiler
# django/db/models/sql/complier.py 23
class SQLCompiler:
def execute_sql(self, result_type=MULTI, chunked_fetch=False, chunk_size=GET_ITERATOR_CHUNK_SIZE):
......
try:
sql, params = self.as_sql() # 生成 SQL 语句和参数
if not sql:
raise EmptyResultSet
except EmptyResultSet:
if result_type == MULTI:
return iter([])
else:
return
# 获取 cursor 游标
if chunked_fetch:
cursor = self.connection.chunked_cursor()
else:
cursor = self.connection.cursor()
try:
cursor.execute(sql, params) # 执行 SQL
except Exception:
# Might fail for server-side cursors (e.g. connection closed)
cursor.close()
raise
# 根据不同的 result_type 返回对应的结果集
......
在 models/sql/complier.py 模块下定义有 5 个 SQL 编译器:SQLCompiler、SQLInsertCompiler、SQLDeleteCompiler、SQLUpdateCompiler、SQLAggregateCompiler,其中后面 4 个编译器都继承自 SQLCompiler。
这 5 个编译器分别用于编译上面的 5 个 Query 对象生成真正执行的 SQL。
在每个编译器的 as_sql 方法中终于可以看到熟悉的 SQL 语法了。as_sql 方法通过 list 存储 SQL 的各个部分,再通过 “ “.join(list) 拼接 list 生成 SQL 字符串返回。
filter 方法的代码流程
上面的代码跳转看起来可能有点乱,再重新梳理一下,一个具体的查询 API 的代码执行流程是怎么样的?
比如定义 User 类继承自 Model,执行 list(User.objects.filter(id=1))
- 调用 ModelBase 的
__new__方法动态创建 User 类,封装 _meta 指向 Option 对象,封装各种 Field 字段 - 如果 User 类没有自定义管理器的话,封装 objects 指向 Manager 包装对象 ManagerDescriptor,Manager 从 QuerySet 继承公共 API 方法,当然也包括 filter
- 调用 Manager 的 filter 方法,即 QuerySet 的 filter 方法
- 调用 Query 的 add_q 方法添加查询条件
- list(QuerySet) 调用 QuerySet 的
__iter__方法,接着调用_fetch_all方法 - 调用 ModelIterable 的
__iter__方法,获取 SQL 编译器 - SQL 编译器生成并执行 SQL
- QuerySet 对结果数据进行 to_python 转换,封装成 User 对象列表。
多数据库支持
通过上面的分析可以知道,Django 的所有增删改查 API 都是调用的 models 模块下的类和方法,但 Django 对多数据库的支持又封装在 backends 模块下,那么 models 和 backends 模块又是怎么连接起来的呢?
先看一下 Django 的 settings 配置文件。
# 数据库配置,可以定义多个别名配置,但必须包含 default 配置,否则 Django 启动时会报错
DATABASES = {
"default": { # 数据库别名
"ENGINE": "django.db.backends.mysql", # 支持 backends 模块下的各种数据库后端
"USER": "root",
"PASSWORD": "root",
"HOST": "127.0.0.1",
"PORT": "3306",
},
"db1": { ... },
"db2": { ... },
}
# 可以自定义路由类,实现 Model 到 数据库别名的映射,如果为空,则所有 Model 都映射到 default 别名
DATABASE_ROUTERS = ["DBRouter"]
我们自定义路由类如下:
class DBRouter:
# 传入 Model 类,返回数据库别名,实现了 Model 到数据库后端的映射
def db_for_read(self, model, **_):
return "db1"
def db_for_write(self, model, **_):
return "db2"
再看 Django 的 ConnectionRouter 类源码:
# django/db/utils.py 228
class ConnectionRouter:
@cached_property
def routers(self):
if self._routers is None:
self._routers = settings.DATABASE_ROUTERS # settings 配置文件的路由配置
......
def _router_func(action):
def _route_db(self, model, **hints):
chosen_db = None
for router in self.routers:
......
instance = hints.get('instance')
if instance is not None and instance._state.db:
return instance._state.db
return DEFAULT_DB_ALIAS # 如果没有自定义路由,默认返回 default
return _route_db
db_for_read = _router_func('db_for_read')
db_for_write = _router_func('db_for_write')
通过配置文件,自定义路由和 ConnectionRouter 类,就实现了 Model 类到数据库别名再到数据库后端的映射了。
我们知道,QuerySet 是惰性计算的,最终的 SQL 执行其实都是通过 ModelIterable 类进行的。
所以回看 ModelIterable 的 __iter__ 方法,可以看到 QuerySet 的 db 属性(即配置文件的数据库别名)通过 Query 对象一直传递到了编译器中。
但是在 QuerySet 类的源码中却找不到任何地方有设置 db 属性的,所以我的猜测是:QuerySet 的所有 API 方法都会被复制到 Manager 类中(回看 BaseManager 的 _get_queryset_methods 方法),所以 QuerySet 的 API 调用都是通过 Manager 这个代理来进行的,db 属性应该定义是在 Manager 类中。
回看 BaseManager 的 133 行的 db 方法,Manager 封装了 Model 类,自然可以通过 Model 类拿到数据库别名了。
至此,Manager 和 backends 模块就连接起来了。总结一句话,models 和 backends 模块是通过 ConnectionRouter 类连接起来的。
总结
Django ORM 的代码量很多,所以这里忽略了很多具体细节,侧重于梳理一些重要的类以及它们之间是如何连接交互的。
这里面还有一些问题是没有研究透的,先记录下,以后有时间再继续研究:
- 上面提到的各个类的生命周期是怎样的
- 数据库连接是如何管理的
- QuerySet 如何将结果集转换成 Python 对象